We frequently get asked why we’re building text (code) processing software in Rust and not in Python since our performance would be bottlenecked by the LLM inference anyway. In this article I’ll do some exploration on the performance of our Rust based indexing and querying pipeline, and how it compares to Python’s Langchain. In this specific scenario our tool is significantly faster, which we didn’t really expect, so I dove in and found out why.
Our motivation for using Rust to implement Swiftide is manifold: we want to build a fast and efficient toolchain, and we want to have it be reliable and both easy to write and maintain. Rust checks all these boxes, the ecosystem is strong and constantly growing and the tooling is excellent.
Realistically, although Rust boasts performance benefits like zero-cost abstractions and fearless concurrency, that doesn’t mean it’s going to make your project run ten times faster. As fast as the Rust code could be, when you’re dealing with large language models you’ll still be waiting on those GPUs crunching away. When choosing Rust, the performance of the language itself can’t be the only motivation, and it wasn’t for us. However, we’d be embarrassed if we’d built our Swiftide library and it turned out to be slower than similar Python projects so we set out to establish a baseline benchmark.
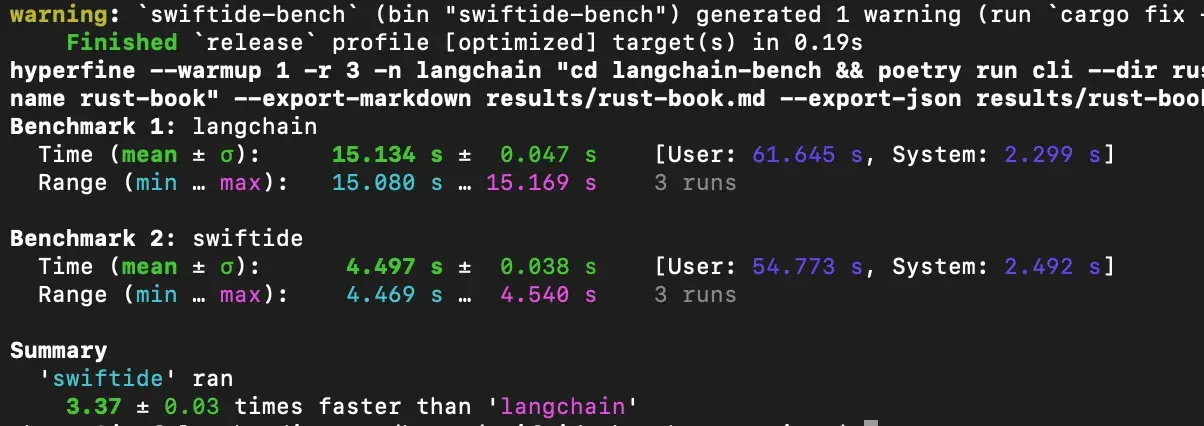
In this benchmark we attempt to stress the framework and processing code while still keeping the workload realistic. The assignment is simple: process a dataset of text, generate embeddings for it, and then insert the embeddings into a vector database. We’ll be using Qdrant for the vector database, and FastEmbed for the embeddings. Initially we’ll be focusing on a small dataset, the Rust Book, of which the embeddings take around 3 seconds on an NVIDIA A6000 GPU.
In the flamegraph below you can see just under 90% of the time is spent inside the ONNX runtime running computing those embeddings.

If in Rust we’re spending 90% of the time in the ONNX runtime, then why is Langchain spending around
3 times that amount performing roughly the same work? To answer this I ran the code through the cProfile module, and
opened up the resulting profile in snakeviz. Clicking around a bit reveals the big culprit:
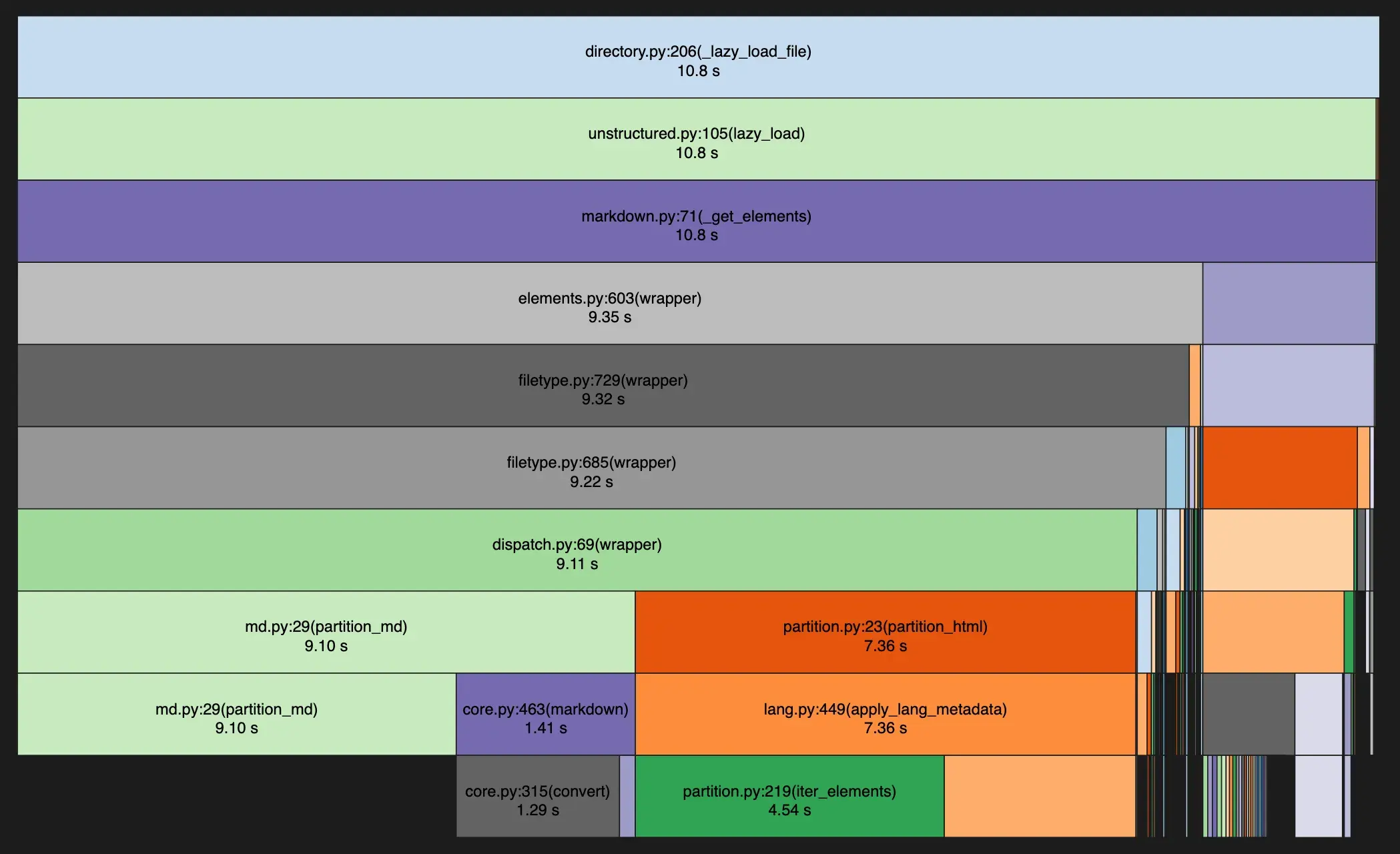
The langchain pipeline is spending a solid 10 seconds in the Markdown and HTML partitioning step. In
the Swiftide version we were only using a Markdown parser when chunking is enabled, so this is an
unfair comparison. The situation is quickly rectified by switching to the plain TextLoader in Langchain.
I could have left this run out of the article, as it was just a mistake on my part in setting up the benchmark but I think it’s important to reflect on how easy it was to get this benchmark to be suddenly bound by the CPU by invoking an inefficient (and in this case unnecessary) preprocessing step.
When we now re-run the benchmark with the TextLoader we see a slightly more reasonable performance difference:
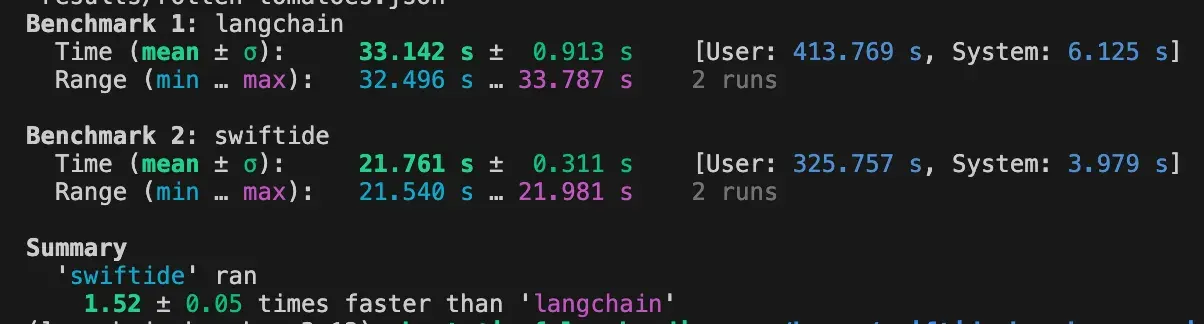
To put a bit more pressure on the frameworks, I switched to the medium sized benchmark (Rotten Tomatoes) for this comparison, which is why it is taking a little bit longer. The ONNX FastEmbed step is now taking around 20 seconds.
Langchain is a lot closer to Swiftide, but there is still a significant difference. A quick look at the snakeviz profile reveals that there is now more of a death by a thousand cuts situation going on:
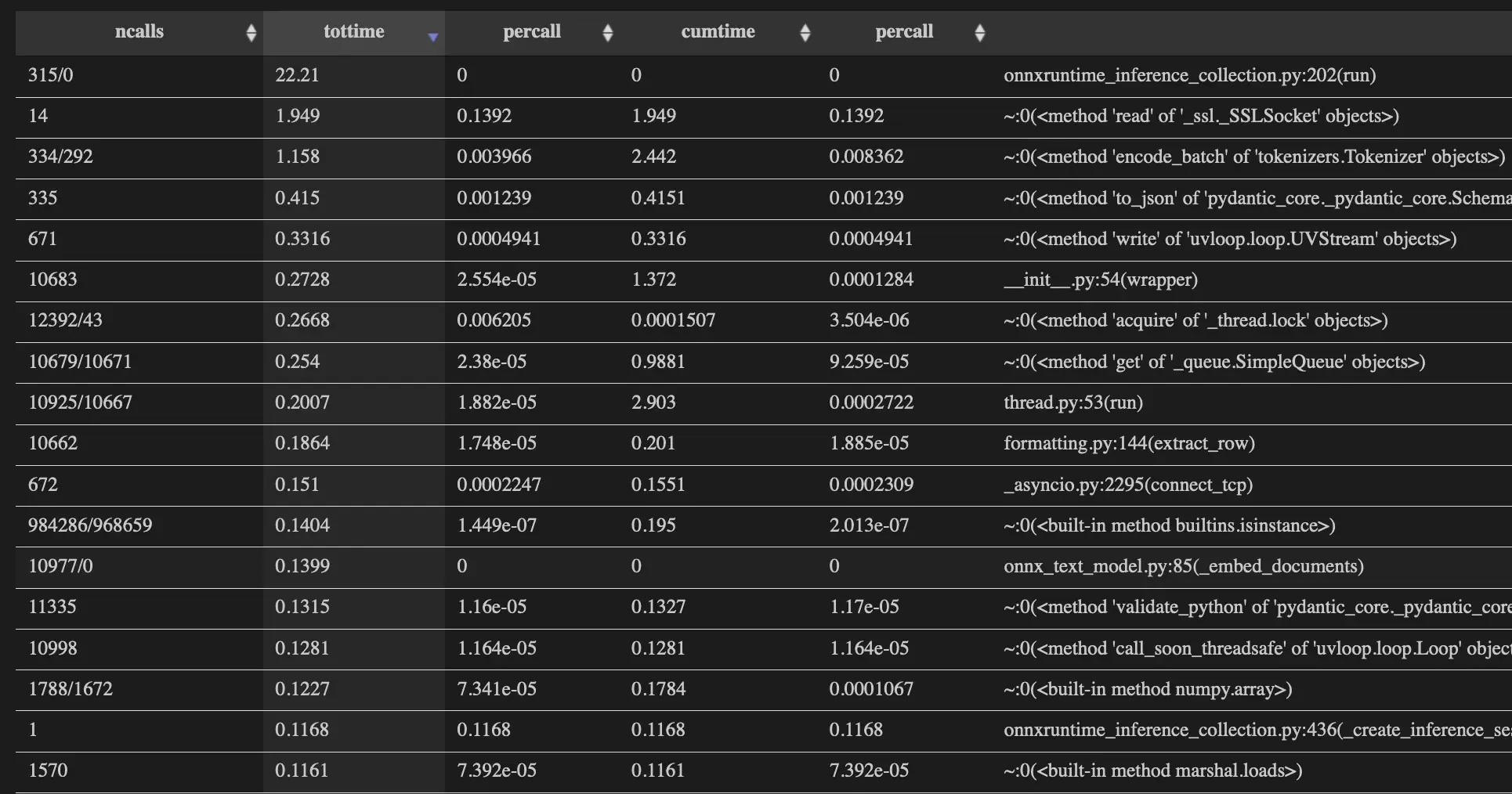
Keep in mind our goal is not really to compare Swiftide and Langchain directly here, just establish a baseline performance metric for Swiftide. The point that I think we should be taking away from this is that the GPU processing step is not necessarily the most expensive, and even if it is there might still be significant time spent elsewhere in your pipeline.
Regardless of what the specifics are of what Langchain or any of the libraries you’re using are doing, it’s likely that Rust could enable you to do it faster. Wether it’s just through easy and safe parallelism, or through fast string processing libraries, Rust has the tools to come near the upper limit of what is possible on your hardware. If that’s useful to you of course depends on your specific needs.
To get started with Swiftide, head over to swiftide.rs or check us out on github.
Discuss on HN Discuss on Reddit
- If you’d like to play around with the benchmarks yourself, you can find the code in this github repository
- Benchmarks for this blog were performed on a NVIDIA A6000 GPU, rented from Hyperstack (not sponsored). The results on the Github Repo were performed on an Apple M1 Max.