In this post, we start by wondering if we can. And then, uncharacteristically, we wonder if we should.
If we want to build a tool that can index a codebase, is that easy to do in Rust? And if we do, could we run the entire thing locally? And if we can, what’s the performance like?
If you’re interested in building language tools, but Python might be on the slow side for your use case, and you’d also like to have more confidence in your code before you run it, Rust is a great choice. As part of Bosun’s mission to eradicate technical debt we are working to make it easy and fast to develop with LLMs in Rust. Our first open source project is Swiftide, a library that lets you build powerful indexing and querying pipelines.
Indexing a codebase using Swiftide, Qdrant, FastEmbed and Ollama
This is what indexing a codebase looks like in Rust using Swiftide:
#[instrument]async fn load_codebase( llm_client: impl SimplePrompt + Clone + 'static, embed: FastEmbed, qdrant: Qdrant, redis: Redis, path: PathBuf,) -> Result<()> { let code_chunk_size = 2048; # we'll be breaking up the code into chunks of 2048 characters
indexing::Pipeline::from_loader( // the file loader will load all files in the path with the supported code extensions FileLoader::new(path.clone()).with_extensions(&SUPPORTED_CODE_EXTENSIONS), ) // we'll use redis to skip files that have already been indexed .filter_cached(redis) // adding full file outlines to the chunks gives them context they // might need to be meaningful .then(OutlineCodeTreeSitter::try_for_language( "rust", Some(code_chunk_size), )?) // the chunker is syntax aware so we're more likely to get meaningful chunks .then_chunk(ChunkCode::try_for_language_and_chunk_size( "rust", 10..code_chunk_size, )?) // to maximize the the quality of the embedding we generate questions and // before embedding answers using the LLM .then(MetadataQACode::new(llm_client.clone())) // embeddings can be batched to speed up the process .then_in_batch(256, Embed::new(FastEmbed::builder().batch_size(256).build()?)) // finally we store the embeddings in QDrant .then_store_with(qdrant.clone()) .run() .await}Note that it’s using some fancy techniques to make sure that the indexing results in a database that actually contains usable information about our codebase. Since code files can be larger than the context window of the LLM, we chunk the code into smaller pieces and embed each chunk seperately. But because a single chunk might be meaningless without its context, we use TreeSitter to extract an outline of the full file and process that together with the chunk. Next we don’t just embed the code, but we ask the LLM to generate metadata about the code in the form of a Q&A. Finally we embed the results of tha Q&A in the vector store which is QDrant in this case.
As you can probably tell each line in that snippet does a some heavy lifting. Swiftide takes care of parallelizing and batching the work for optimal data flow. And thanks to Rust you’ll be guaranteed at compile time that you’ve got all your variable names, data shapes and function invocations right.
Alright, so now that we’ve got our codebase indexed, how do we get information out of it? Here’s a snippet to do just that using Swiftide’s new query pipeline:
#[instrument]async fn ask( llm_client: impl SimplePrompt + Clone + 'static, embed: FastEmbed, qdrant: Qdrant, question: String,) -> Result<String> { let pipeline = query::Pipeline::default() // we start by generating subquestions from the question to maximize // the chance of getting relevant results .then_transform_query(query_transformers::GenerateSubquestions::from_client( llm_client.clone(), )) // these are then embedded and used to retrieve the embeddings from QDrant .then_transform_query(query_transformers::Embed::from_client(embed)) .then_retrieve(qdrant.clone()) // each result is summarized to condense the information .then_transform_response(response_transformers::Summary::from_client( llm_client.clone(), )) // finally we feeed the summarized responses into the LLM to generate an answer .then_answer(answers::Simple::from_client(llm_client.clone()));
let result = pipeline.query(question).await?;
Ok(result.answer().into())}By the way, you can find the full code of this example in the Swiftide-Ask repository.
In this snippet you can see that we’re not just embedding the question, but we’re first generating subquestions from it. Generating subquestions will allow the embedding to be closer to that of the code and generated metadata in the database. We then retrieve the embeddings from the database and transform the response into a human readable summary. Finally we answer the question using the LLM.
I believe that these two snippets show how powerful Rust can be for building language tools. Note that
the first argument of these functions is the llm_client which has to implement SimplePrompt.
Swiftide comes with a bunch of implementations of this trait, besides OpenAI, Groq and every model on
AWS Bedrock, it also has one for Ollama. Let’s plug that one in and see how it performs.
let llm_client = integrations::ollama::Ollama::default() .with_default_prompt_model("llama3.1") .to_owned();Besides adding that single line of Rust (and enabling the feature in the swiftide package) it’s also necessary to install and run the Ollama service. On my Mac it was a simple click and drag to install, for detailed instructions for your platform check out Ollama.
Make sure the model you need is available in the Ollama service. If you’re using the llama3.1 model
you can start it with the following command:
ollama run llama3.1If you’ve cloned the Swiftide-Ask repository you can run the example with the following command:
RUST_LOG=swiftide=debug cargo run "What database is used to store the embeddings?"If you run this in the Swiftide-Ask repository and you’re running on an M1 Mac or faster it should run for a couple of minutes and then give you an answer. For large codebases it will take a very long time, but thanks to Swiftide’s caching system it will be nearly instant on subsequent runs.
Analyzing the pipeline using OpenTelemetry and Jaeger
Many crates in the Rust ecosystem support the tracing framework for diagnostics. Swiftide is no
exception, and we can easily enable it and redirect the output to an OpenTelemetry compatible
sink like Jaeger:
// the tracer will be used to create spans for each step in the pipelinelet tracer = opentelemetry_otlp::new_pipeline() .tracing() // it will use the OTLP tonic exporter to send the traces to Jaeger .with_exporter(opentelemetry_otlp::new_exporter().tonic()) // and it will use the Tokio runtime .install_batch(opentelemetry_sdk::runtime::Tokio) .expect("Couldn't create OTLP tracer") .tracer("swiftide-ask");
// we create a tracing layer that uses the tracerlet otel_layer = tracing_opentelemetry::layer().with_tracer(tracer);
// and register it as a global tracing subscribertracing_subscriber::registry() .with(tracing_subscriber::EnvFilter::from_default_env()) .with(otel_layer) .init();Besides enabling the tracing layer we can also annotate our functions with #[instrument] to get
contextualize traces within our own code.
Then we simply run:
docker run -d --name jaeger -e COLLECTOR_OTLP_ENABLED=true -p 16686:16686 -p 4317:4317 -p 4318:4318 jaegertracing/all-in-one:latestTo get a Jaeger instance running, and then run swiftide-ask again like this:
OTEL_SERVICE_NAME=swiftide-ask RUST_LOG="swiftide=debug,h2=warn" cargo runNow we can inspect our run in Jaeger by going to http://localhost:16686.
Running with Ollama on my Apple M1 Pro I got the following trace:
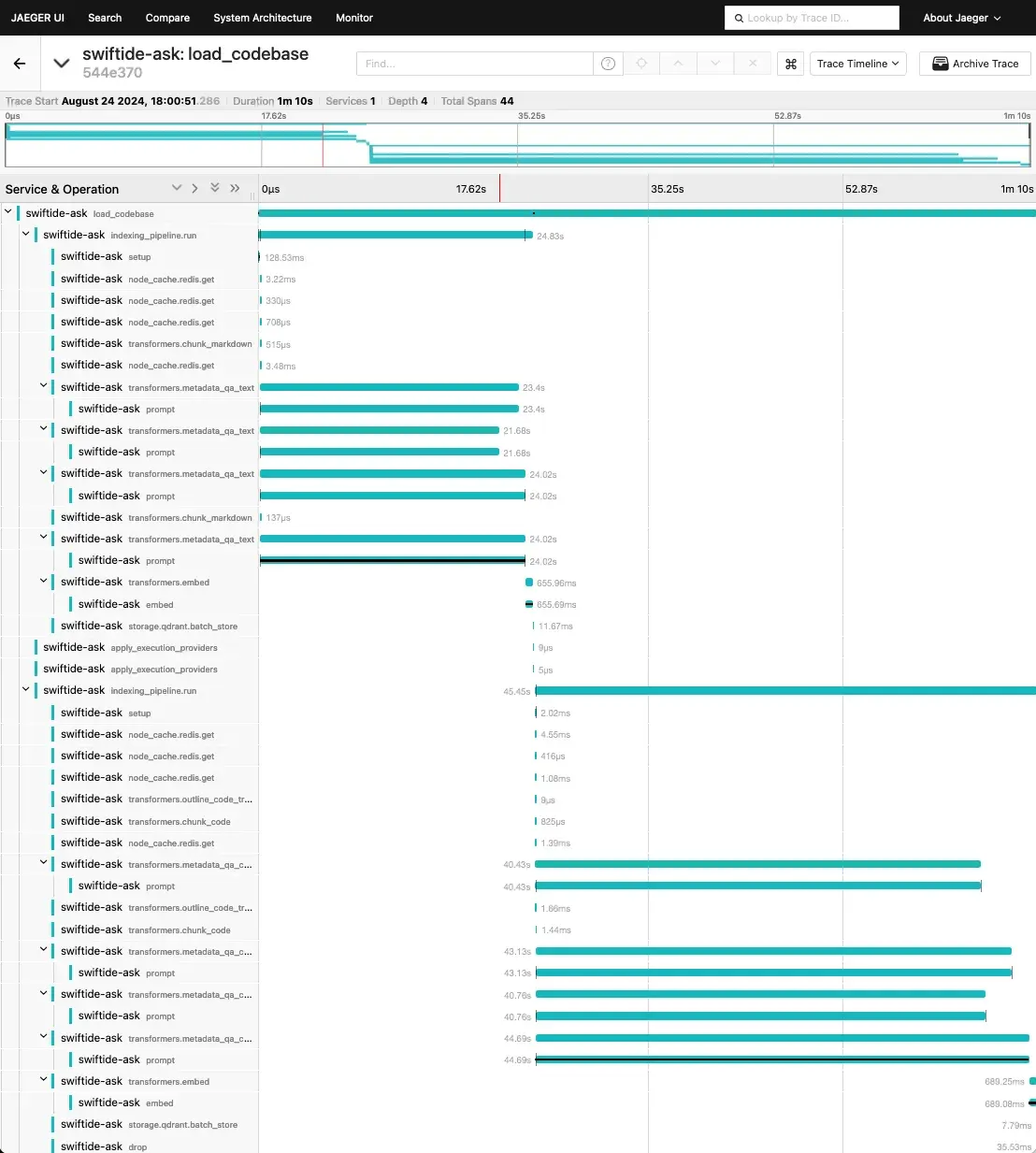
As you can tell from each prompt taking about 40 seconds, using an underpowered machine won’t be a very good experience. Going off performance benchmarks posted online, it seems going with the Ultra versions of Apple chips should be about 4 times as fast. Still not very good but possibly manageable for small codebases.
Just to show what performance is possible, let’s also run it in the same way but with the Groq model:
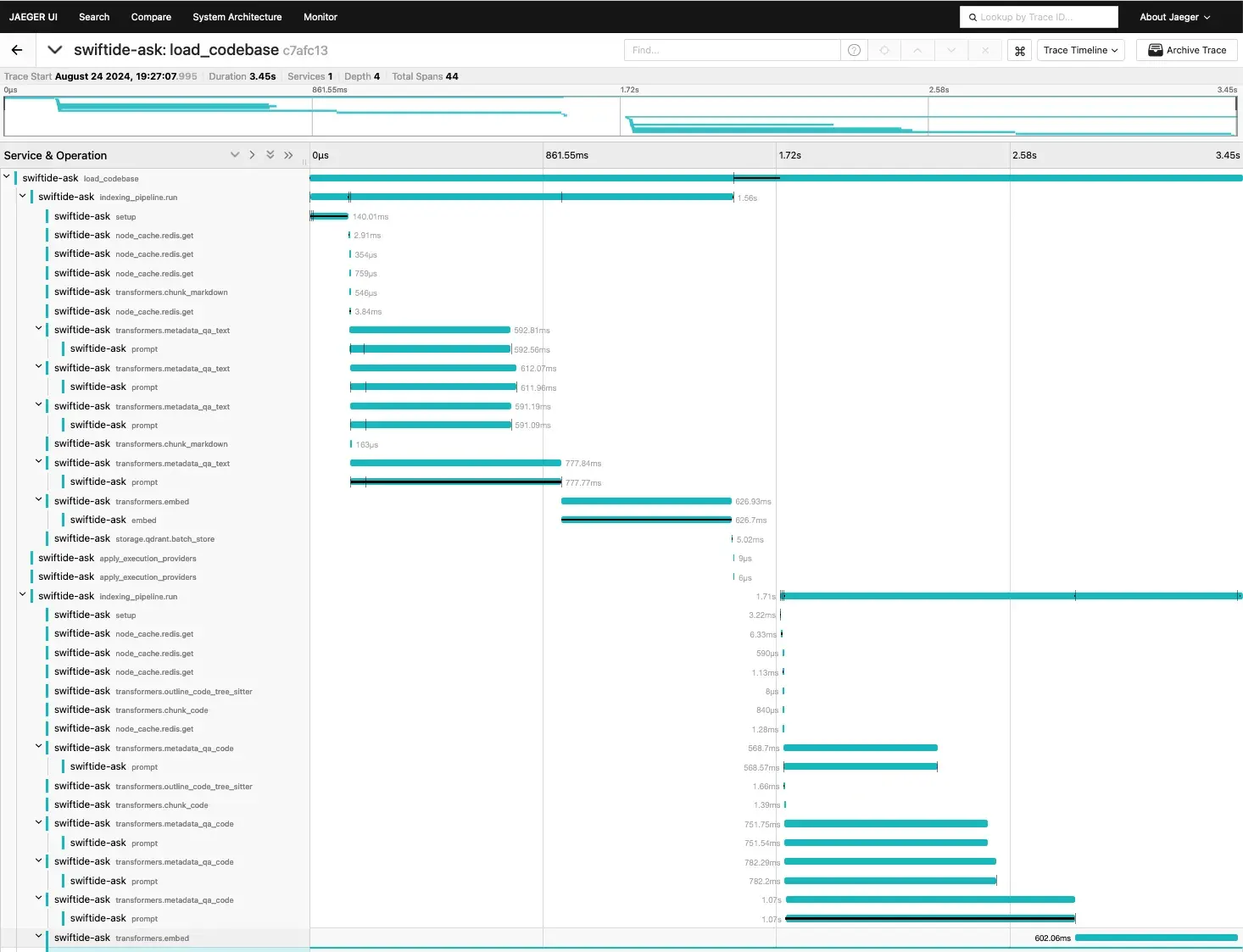
Now every prompt takes just around 600ms, which makes it a lot more realistic to run over a large codebase. The indexing pipeline on swiftide-ask itself took just 4 seconds.
Conclusion
We’ve built a quick code intelligence retrieval engine using Rust and Swiftide. Experimented with Ollama and Groq as LLMs to back it, using OpenTelemetry and Jaeger to trace the performance of the pipeline. At this point we realize that the inference time using a service like Groq is two orders of magnitude faster than that of a Mac Pro chip, and that for a large codebase you’d have to reserve quite a bit of time to index it fully locally.