Evaluate Swiftide pipelines with Ragas
Swiftide enables you to build indexing pipelines in a modular fashion, allowing for experimentation and blazing fast, production ready performance for Retrieval Augmented Generation (RAG).
Rust is great at performance and reliability, but for data analytics Python with Jupyter notebooks is king.
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. Evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in.
In this article we will explore how to index and query code, experiment with different features, and evaluate the results.
We only provide snippets for brevity. You can find the full code on github. For the same reason, refer to other posts or our documentation for setting up Swiftide and Python with Jupyter.
To learn more about Swiftide, head over to swiftide.rs or check us out on github
Determining features we want to evaluate
Ragas offers metrics tailored for evaluating each step of the RAG pipeline.
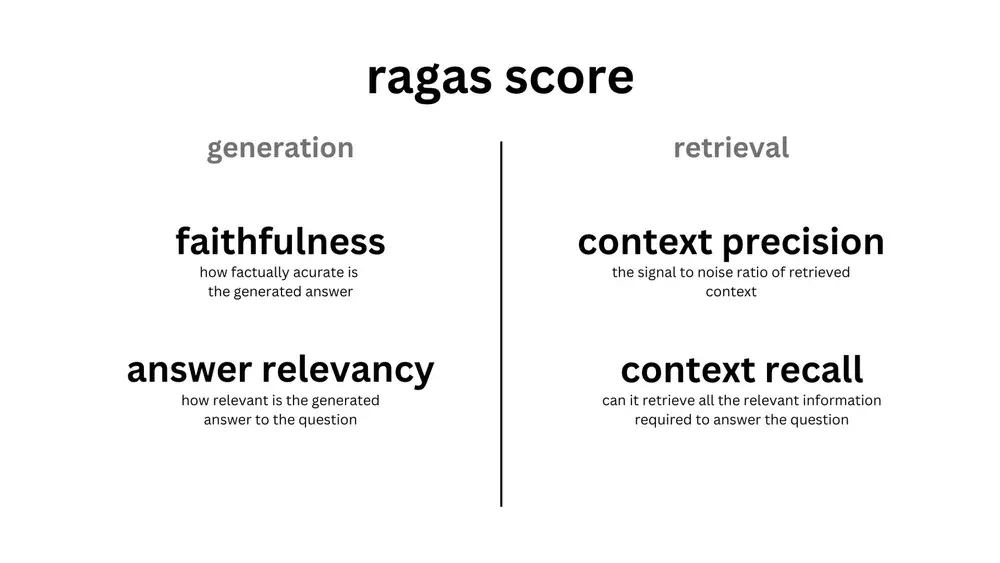
As an example, we want to evaluate what the impact of chunking and synthetic questions are on the performance of the pipeline.
For both of these features enabled individually, together and with neither, we will generate an evaluation for Ragas. We will run the pipelines on the Swiftide codebase and evaluate the results in a python notebook.
In a production setting, you would like evaluate on a much larger dataset, with features that are more complex and have a larger impact.
Laying out the project
We will be building two parts. On the Rust side we will build a query and indexing pipeline that can toggle different features so we can evaluate it. On the Python side we will create a notebook that takes this output to evaluate and plot the results with Ragas.
The Rust part
For this example, we will set up a project with the following features:
- A code and markdown indexing pipeline that optionally:
- Chunks into smaller parts
- Adds metadata with synthetic questions
- A query pipeline
- Generates subquestions to increase the semantic coverage
- Retrieves documents to generate an answer
- Clap for command line arguments
- A ragas evaluator that exports to the ragas format
Setting it up
First, let’s create the crate with all the dependencies we need:
$ cargo new swiftide-with-ragas$ cd swiftide-with-ragas$ cargo add clap tokio anyhow swiftide tracing-subscriber \ --features=clap/derive,tokio/full,swiftide/qdrant,swiftide/openai,swiftide/tree-sitterNext, let’s set up a main function, with clap, to kick it off:
const COLLECTION_NAME: &str = "swiftide-ragas";
#[derive(Parser, Debug)]#[command(version, about, long_about = None)]struct Args { #[arg(short, long)] /// Language of the code to index language: String,
#[arg(short, long, default_value = "./")] /// Path to the code to index path: PathBuf,
#[command(flatten)] dataset: DatasetArg,
#[arg(short, long, default_value = "false")] /// Records answers as ground truth record_ground_truth: bool,
#[arg(short, long)] /// Output file to write the evaluation results to output: PathBuf,}
#[derive(clap::Args, Debug, Clone)]#[group(required = true, multiple = false)]struct DatasetArg { /// Dataset json file to load questions and ground truths from #[arg(short, long, conflicts_with = "questions")] file: Option<PathBuf>, /// List of questions to use for evaluation questions: Option<Vec<String>>,}
struct Context { openai: OpenAI, qdrant: Qdrant,}
#[tokio::main]async fn main() -> Result<()> { tracing_subscriber::fmt::init();
let args = Args::parse();
// Initialize the OpenAI client let openai = OpenAI::builder() .default_embed_model("text-embedding-3-small") .default_prompt_model("gpt-4o-mini") .build()?;
// Initialize the Qdrant client let qdrant = Qdrant::builder() .vector_size(1536) .collection_name(COLLECTION_NAME) .build()?;
let context = Context { openai, qdrant };
// Delete the collection if it already exists force_delete_qdrant_collection(&context).await?;
// Index the code and any markdown index_all(&args.language, &args.path, &context).await?;
// Either load the dataset from a file or use the questions provided // Then create the evaluation dataset to be used let dataset: EvaluationDataSet = if let Some(path) = args.dataset.file { std::fs::read_to_string(path)?.parse()? } else { args.dataset .questions .ok_or(anyhow::anyhow!("Expected questions"))? .into() };
// Query the indexed dataset and return the evaluation let evaluation = query(dataset, args.record_ground_truth, &context).await?;
// Write the evaluation to a json file so it can be used in the python notebook let json = evaluation.to_json().await; std::fs::write(args.output, json).context("Failed to write ragas.json")?;
Ok(())}
// Ensure we start with a clean slate every timeasync fn force_delete_qdrant_collection(context: &Context) -> Result<()> { let _ = context .qdrant .client() .delete_collection(COLLECTION_NAME) .await;
Ok(())}Indexing the repository
Next the fun part. In the Cargo.toml, add a chunk and metadata feature, and include them in default:
[features]default = ["chunk", "metadata"]chunk = []metadata = []Now we can implement the index_all function. It loads files from the given path, markdown or code, splits the stream by the extension, then conditionally chunks and adds metadata to the nodes. It then merges the stream, batch embeds them with openai and stores it into Qdrant.
async fn index_all(language: &str, path: &PathBuf, context: &Context) -> Result<()> { tracing::info!(path=?path, language, "Indexing code");
let language = SupportedLanguages::from_str(language)?; let mut extensions = language.file_extensions().to_owned(); extensions.push("md");
// Index all code and markdown files in the provided directory let (mut markdown, mut code) = Pipeline::from_loader( FileLoader::new(path).with_extensions(&extensions), ) .split_by(|node| { // Any errors at this point we just pass to 'markdown' let Ok(node) = node else { return true };
// On true we go 'markdown', on false we go 'code'. node.path.extension().map_or(true, |ext| ext == "md") });
// For each feature that we want to test, enable them conditionally if cfg!(feature = "chunk") { code = code // Uses tree-sitter to extract best effort blocks of code. We still keep the minimum // fairly high and double the chunk size .then_chunk(ChunkCode::try_for_language_and_chunk_size( language, 50..1024, )?);
markdown = markdown.then_chunk(ChunkMarkdown::from_chunk_range(50..1024)); }
if cfg!(feature = "metadata") { code = code.then(MetadataQACode::new(context.openai.clone())); markdown = markdown.then(MetadataQAText::new(context.openai.clone())); }
// Merge both pipelines and generate embeddings code.merge(markdown) .then_in_batch(50, Embed::new(context.openai.clone())) .then_store_with(context.qdrant.clone()) .log_errors() .run() .await}Querying the data
We also need to provide a query pipeline so we can query the data we indexed. This is also where the evaluator will jump in. Ragas primarily uses questions, answers, retrieved documents and ground truth (if provided) as its source for evaluation.
In Swiftide, an evaluator can be hooked into the query pipeline. Additionally, we provide a way to record the answers as ground truth to include it in our export as a baseline.
async fn query( questions: EvaluationDataSet, record_ground_truth: bool, context: &Context,) -> Result<evaluators::ragas::Ragas> { // Create a new evaluator with prepared questions, either from the input file or the provided // questions let ragas = evaluators::ragas::Ragas::from_prepared_questions(questions);
// Run a query pipeline that answers all provided questions let pipeline = query::Pipeline::default() .evaluate_with(ragas.clone()) .then_transform_query(GenerateSubquestions::from_client(context.openai.clone())) .then_transform_query(query_transformers::Embed::from_client( context.openai.clone(), )) .then_retrieve(context.qdrant.clone()) .then_answer(Simple::from_client(context.openai.clone()));
pipeline.query_all(ragas.questions().await).await?;
// If the flag is set, record the answers as ground truth. // Ragas needs to know the correct answers to evaluate certain metrics. // // Can also be set manually or have RAGAS handle it. There are pros and cons to each. if record_ground_truth { ragas.record_answers_as_ground_truth().await; }
Ok(ragas)}You can find the full code for this example on github.
Setting up a Python notebook
Now it’s time to do some experimentation with a notebook. Make sure you have Python setup, either globally or using venv, poetry or uv, with Jupyter installed. You will also need ragas, datasets, pandas, seaborn and matplotlib.
Then run jupyter notebook to create a new notebook and open it. In the examples repository, you can find a questions.json with a large amount of synthetic questions for the Swiftide project. You can also use the example code there to generate your own.
Generating our data
First, we will generate our ground truths with all features enabled, some questions, and exporting the results to base.json.
Run with all features and use the answers as the ground truths
!RUST_LOG=swiftide=info cargo run -- --language rust --path . --output base.json \ --record-ground-truth \ "How is swiftide used?" \ "How are arguments passed?" \ "How is Ragas used?"Next we let’s run it for each feature, use the base.json as input, and export to separate json files:
Run with chunking enabled and QA metadata disabled
!RUST_LOG=swiftide=info cargo run --no-default-features --features=chunk -- \ --language rust --path . --output metadata.json --file base.jsonRun with chunking disabled
!RUST_LOG=swiftide=info cargo run --no-default-features --features=metadata -- \ --language rust --path . --output chunk.json --record-ground-truth --file base.jsonRun with chunking and metadata disabled
!RUST_LOG=swiftide=info cargo run --no-default-features -- \ --language rust --path . --output nothing.json --record-ground-truth --file base.jsonLoading the data
We need to merge the separate json files into a single dataset.
Load all the data using datasets:
from datasets import load_datasetfiles = { "everything": "base.json", "metadata": "metadata.json", "chunk": "chunk.json", "nothing": "nothing.json"}dataset = load_dataset("json", data_files=files)
datasetEvaluating with Ragas
For each dataset we can now run the evaluation. After that we combine it into a single pandas dataframe so we can explore the evaluation and visualize it.
from ragas.metrics import ( answer_relevancy, faithfulness, context_recall, context_precision,)
import pandas as pd
from ragas import evaluate
ragas_metrics = [answer_relevancy,faithfulness,context_recall,context_precision]
# Run evaluate on each dataset, add a column with the dataset name,# then concat into single dataframeall_results = []for key in files: result = evaluate(dataset[key], metrics=[ragas_metrics]).to_pandas() result['dataset'] = key all_results.append(result)
df = pd.concat(all_results)dfFinally, some graphs
Finally some graphs. Let’s generate a bar chart and heatmap on the mean of each feature:
import seaborn as snsimport matplotlib.pyplot as plt
# Grouping by dataset and calculating the meandf_grouped = df.groupby('dataset').mean(True).reset_index()
# 1. Bar Chartdf_grouped.plot(x='dataset', kind='bar', figsize=(12, 6), title='Mean Performance Metrics per Dataset')plt.ylabel('Mean Metric Value')plt.show()
# 2. Heatmapplt.figure(figsize=(10, 6))sns.heatmap(df_grouped.set_index('dataset').T, annot=True, cmap='Blues')plt.title('Performance Heatmap per Dataset')plt.show()And you will have some spiffy graphs!
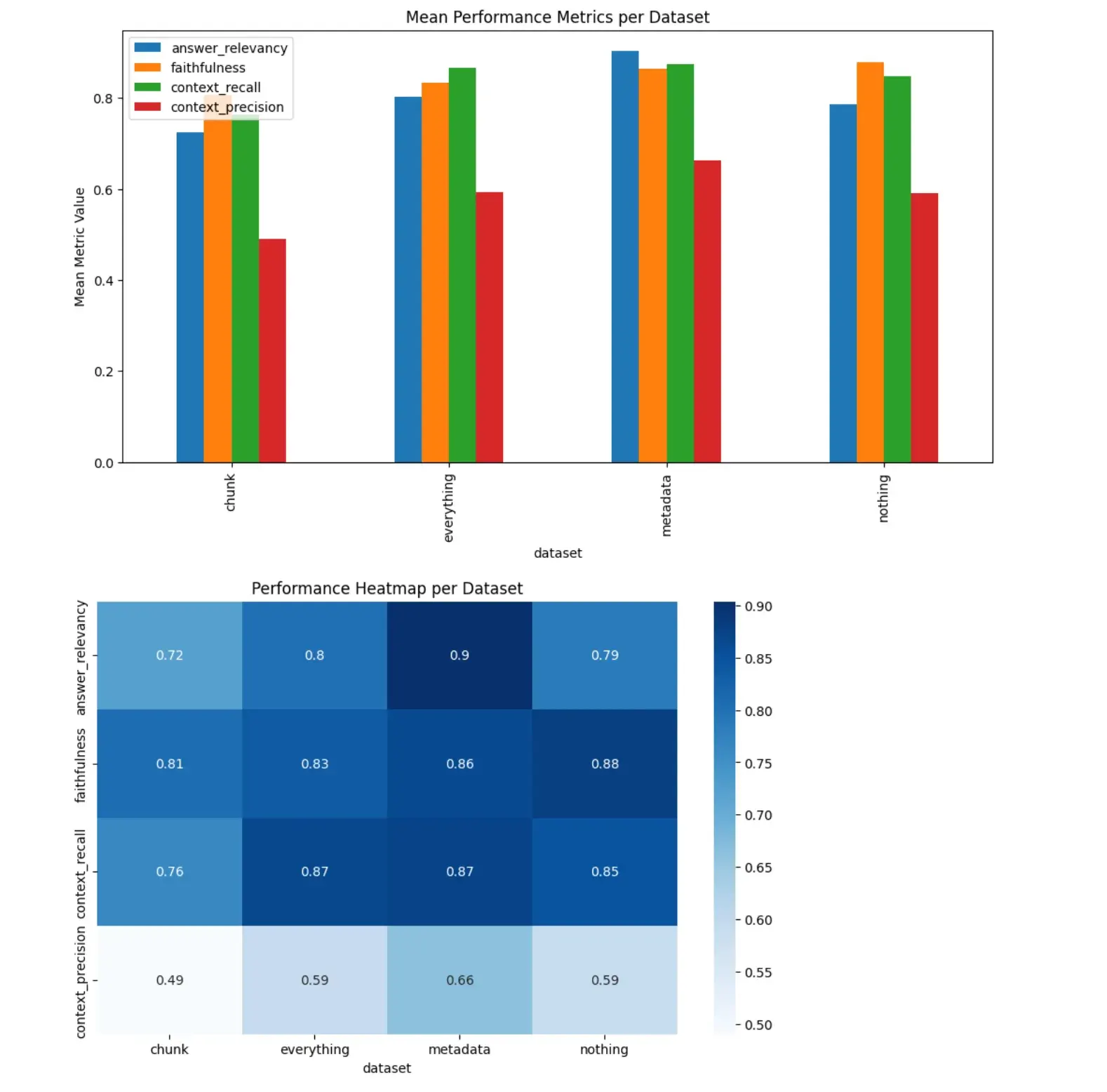
Conclusion
It’s really interesting to see that synthetic question generation has a large impact on the performance of the pipeline. I suspect that because Swiftide has compact files and is not a massive codebase, chunking has less of an impact. In our own future experiments, we will be looking at more complex features, like custom prompt tuning, hybrid search, and more.
Ragas makes evaluating a RAG application straightforward and enables rapid iteration on blazing fast RAG applications build with Swiftide.
Check out the Ragas documentation to see what else they have to offer! The full Rust code and python note book is on github.
To learn more about Swiftide, head over to swiftide.rs or check us out on github